Data-is-the-new-oil is a useful framework for describing one of the use-cases we are developing our platform for.
Rather than their being just one platform in the create-process-deliver-use data analytics pipeline, a number of different platforms are required. The reason we don't fill our cars up with gasoline at our local oil rig is the same reason why data distribution requires a number of different platforms.
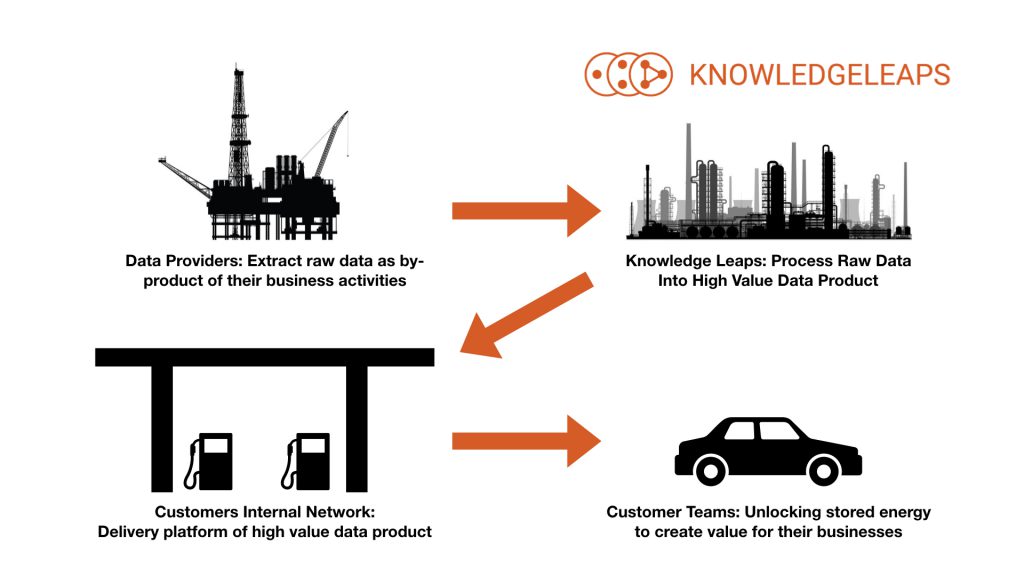
The Knowledge Leaps platform is designed to take raw data from our providers, process and merge these different data feeds before delivering to our customers internal data platforms. Just like an oil-refinery produces the various distillates of crude-oil, the Knowledge Leaps platform can produce many different data products from single or multiple data feeds.
Using a simple UI, we can customize the processing of raw data to maximize the value of the raw data to providers as well as its usefulness to users of the data products we produce.