We are undergoing a site redesign - to improve ease of navigation and make better use of screen real-estate. The first thing our designer did was to make a small change to our logo. It's amazing what a small change can do.
![]()
We are undergoing a site redesign - to improve ease of navigation and make better use of screen real-estate. The first thing our designer did was to make a small change to our logo. It's amazing what a small change can do.
![]()

The weekly ad is beloved and bemoaned by US retailers. On the one hand it is seen as an essential tool in the marketing departments armory. On the other, it is seen as a significant investment that is difficult to measure.
This is exactly the type of pain-point we like to solve at Knowledge Leaps. Using our platform we have built a solution that identifies which promotions get an uplift from appearing in the weekly ad and the incremental $ generated from appearing in the ad.
Adding in meta data about items, ad placement data, and seasonality we can build an AI learning loop for retailers that will optimize and then maximize the return on this investment.

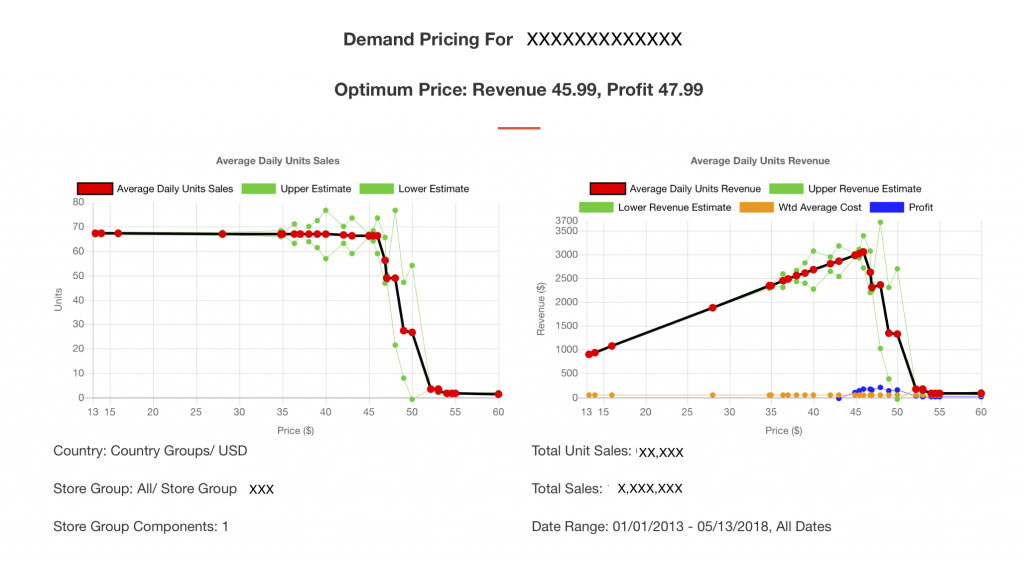
The invention of currency by society is as important as the spread of organized religion. Unlike religion, we have yet to fully grasp the power of price.
Yet for something so important, most companies do not understand the power of price. Firms know how to price items, but pricing strategies are largely built on one of three, arguably flawed, methodologies:
Each method is flawed to some degree, and invariably means firms either leaving money on the table, or do not maximize sales in a competitive context.
Knowledge Leaps has created an algorithm to estimate the optimum pricing based on consumer demand. The platform can evaluate price in different contexts (peak vs. off-peak seasons, stand-alone pricing Vs competitive context pricing, test vs. control stores, and by different audiences).
Using our algorithm we can quickly evaluate multiple items across multiple store groups in multiple territories/countries to identify optimum price zones.
Overlaying machine learning the KL platform will identify how a retailer can increase profit at a transaction level and then test it in the market place to explore any unintended consequences of price changes.
You can have a pretty good guess at someone's age based on purely on the number of web domains they have purchased and keep up to date. I have 46 and I bought another one, the other day, RoboCoworker.com. I had in mind an automated coworker that could offer a sense of companionship to freelancers and solo start-up founders during their working day. It's semi-serious and I put these thoughts to one side as I got back to some real work.
Today, I had a call with a prospect for Knowledge Leaps. I gave them a demo and described the use-cases for their industry and role. It dawned on me, that I was describing and automated coworker, a RoboCoworker if you will.
This wouldn't be someone you can share a joke or discuss work issues with, but would be another member of your analytics team that does the work while you are in meetings, fielding calls from stakeholders, or selling in the findings from the latest analysis. What I call real work that requires real people.

Once brands and companies embrace data, the biggest challenge they face for long term growth, and survival, is ensuring the data they control has a broad scope - i.e. it allows them to look to their edges of their vertical, and beyond. When Warren Buffet chooses firms to invest in, he looks at what he describes as their moat, either an economic, ip-related or technological moat. A firm's moat helps insulate them from attack, and allows companies to weather economic downturns. In the data age, building broad scope data sources is an extra moat for firms.
Most companies in established verticals are either competing with Amazon or worried they will end up competing with Amazon. As with Google, Amazon gets a wide and detailed view of customer behaviors and trends from its many businesses. Just three of those business units, online store, web services and amazon video, provide a rich understanding of consumers and their preferences that Amazon can use to identify opportunities for launch new businesses.
Amazon is clearly ahead of the game, and if they don’t make a misstep the lack of real competition this early on will no doubt allow the power law of growth to take hold in many verticals. As Marc Andreessen wrote in 2011, “Software is eating the world”, Amazon is doing just this. No doubt Google and Facebook are on a similar path and are equally hungry.
For the rest of the commercial world, sage advice would be to build broad scope data sources that you control, rather than just enhancing analytics capabilities. Data sources that provide insight into incremental audiences are crucial to audience and sales growth.
Firms should invest in creating new behavioral datasets that they can control (analyze, shape, create experiments with). Ultimately future success will be determined by whether firms can create demand for their products by changing people’s behaviors and create incremental audiences. Looking beyond their verticals, and thinking about the growing their categories is key to this. This can only be achieved successfully by committing to a data strategy that encompasses, developing broad scope and deep data sources as well as advanced analytics.
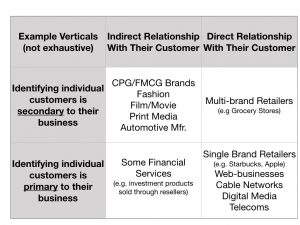
I think a lot about data and about different types of data and who is using it. I produced this table that classifies the relationship with data for firms in different verticals. It also shows the relationship between the use of survey data and the use of behavioral data to understand the performance of their business. Those firms that haven't traditionally required identifying a customer as an individual have had a greater reliance on survey data to understand their customer the those firms where you require an account to buy from them.
All firms use $ sales and profit to measure their performance, but along the way firms need proxy measures - these are either going to come from behavioral data (clicks, foot traffic, etc) or from proxy measures (customer satisfaction gather in surveys).
As more businesses have become customer-data-centric if not fully customer-centric, there has been an increasingly reliance on customer behavioral data rather than survey data to measure performance.
Over the past decade this has been driven by many firms moving from the top-left quadrant to the bottom-right quadrant, notable examples are Apple and many video game developers and publishers.
I wonder if there is a performance inflection point? For example is there a threshold value for the proportion of your customer base that you have a relationship with, above business performance weakens, especially in markets where there isn't a monopoly and near-monopoly. Since customers are always churning, customer acquisition is key to driving sales growth. However, having a known pool of customers (current and lapsed) could breed a sense of complacency in firms. Contrast that with firms who do not have a direct relationship with their customers, this induces a certain degree of paranoia that puts customer retention and acquisition at the top of their agenda.

The attraction of AI is that it is learns by experience. All learning requires feedback, whether its an animal, a human or a computer doing the learning, The learning-entity needs to explore its environment in order to try different behaviors, create experiences and then learn from them.
For computers to learn about computer-based environments is relatively easy. Based on a set of instructions, a computer can be trained to learn about code that it is executing or is being executed by another computer. The backbone of the internet uses something to similar to ensure data gets from point A to point B.
For humans to learn about human-environments, this is also easier. It is what we have been doing for tens of thousands of years.
For humans to learn about computer-based environments is hard. We need a system to translate from one domain into another. Then we need a separate system to interpret what we have translated. We call this computer programming, and because we designed the computer, we have a bounded-system. There is still a lot to understand, but it is finite and we know the edges of the system, since we created it.
It is much harder for computers to learn about human environments. The computer must translate real-world (human) environment data into its own environment, and then the computer needs to decode this information and interpret what it means. Because the computer didn't design our world it doesn't have the advantage that humans do when we learning about computers. It also doesn't know if it is bounded-system or not. For all the computer knows, the human-world is infinite and unbounded - which it could well be.
In the short term, to make this learning feasible we use human input. Human's help train computers to learn about the real-world environments. I think of the reasons that driver-less car technology is being focused on, is that the road system is a finite system (essentially its 2D) that is governed by a set of rules.
•Don't drive into anything, except a parking spot.
•Be considerate to other drivers, e.g. take turns at 4-way stop signs.
•Be considerate to pedestrians and cyclists.
•etc
This combination of elements and rules makes it a perfect environment to train computers to learn to drive, not so much Artificial Intelligence but Human-Assisted Intelligence. Once we have trained a computer to decode the signals from this real-world environment and make sensible decisions with good outcomes, we can then apply this learning to different domains that have more variability in them, such as delivering mail and parcels.
This is very similar to the role of the machine screw in the industrial revolution. Once we had produced the first screw, we could then make a machine that could produce more accurate screws. The more accurate the screw, the more precise the machine, the smaller tolerance of components it could produce, the better the end-machine. Without the machine screw, there would have been no machine age.
This could open the doors to more advanced AI, it is some way off though because time required to train computers to learn about different domains.

I've been analyzing data for 30 years.
I've studied science and engineering.
I read about science.
I taught myself to code and created a data engineering and analytics web application (KnowledgeLeaps.com).
I have thought a lot about my work as I have developed my domain expertise.
One of the things I have come to realize is that if you are designing and running experiments to prove / disprove a hypothesis, then you are performing science. You may even call yourself a scientist. Testing a hypothesis requires evidence, usually in the form of objective data. If you are a scientist, you use data, no matter what the discipline. You can't be a scientist without data. The term data in Data Science is redundant, like calling yourself a Religious Priest or an Oral Dentist.
In contrast, if you use data to look for a story or a correlation (causal or otherwise) and you aren't testing a hypothesis. You aren't a scientist, you are an analyst. In this case a qualifying noun is useful (data, systems, etc).
I suspect most people who call themselves data scientists are actually analysts that have taught themselves to write code. This isn't science. Science is the method by which we create persistent state knowledge, code is just a tool we should use to process data to test a hypothesis.

While keeping people in silos is a good thing for managing and directing them, it tends to be bad for business in the long run. Especially for businesses that rely on innovation for growth.
In the book, The Medici Effect, the author describes how the wealthy 14th century house of Medici created the conditions that led to the Renaissance - a period when there was an explosion of ideas across the arts and sciences. This was only possible because the family's wealth was able to support artists from different disciplines who shared ideas, a lesson to companies that want to innovate.
What's true of people is also true of data. Not all data is created equally. As a result it tends to be put in silos determined by source (transactions, surveys, crm, etc). Different data has different degrees of meaningfulness; transaction data tends to be narrow but very deep (telling you a lot about a very narrow field) whereas survey data tends to be broad but less deep. Combining data with different strengths can uncover new insights. Linking transaction data with survey data can identify broader behavior drivers, these can drive sales and increase customer engagement.
In our mind, silos are bad for data too. They prevent data owners from making new discoveries that arise from merging a customer's data.
Knowledge Leaps de-silos your data, creating a single-customer view. Allowing companies to look at the drivers, interactions and relationships across different types of data, whether its transactions, surveys or CRM data.

Spending time with people in different professions and trying to do their jobs is an effective way of innovating new ideas. This is very different to talking to people about what they do in their job, unless of course you are talking to someone who is very self-aware about the pain points in their current job's functions.
Over the past year, this is what we have been doing with Knowledge Leaps. Rather than invest money in building "cool" features, we have been taking the following approach:
The Use it phase goes beyond testing functionality, we are testing the applications performance envelope as well as it usability and seamless-ness. Using the product to do actual work on actual data - i.e. doing the job of an analyst - is central to developing and innovating a useful and useable product.
Along the way I have learnt some lessons about myself too:
We plan to keep this process up as we roll-out new features - advanced reporting, audience identification, and beyond.
