Not all variables in a data set or questions in a survey are equal when it comes to data analysis and analytics. Some variables (questions if it’s a survey) will be inherently better at classifying outcomes than others. For example, if you are using a data set to build a narrative around a particular binary behavior (i.e. people who do X vs people who don't do X) then there are some considerations about which variables will give you a short cut to the story.
The first rule of thumb is to start with binary predictors, i.e. variables with only two different responses / values. Variables with a greater number of possible responses/values will be more likely to have spurious relationships with the variable that you are trying to predict. Predictors with two levels are less likely to suffer this phenomena.
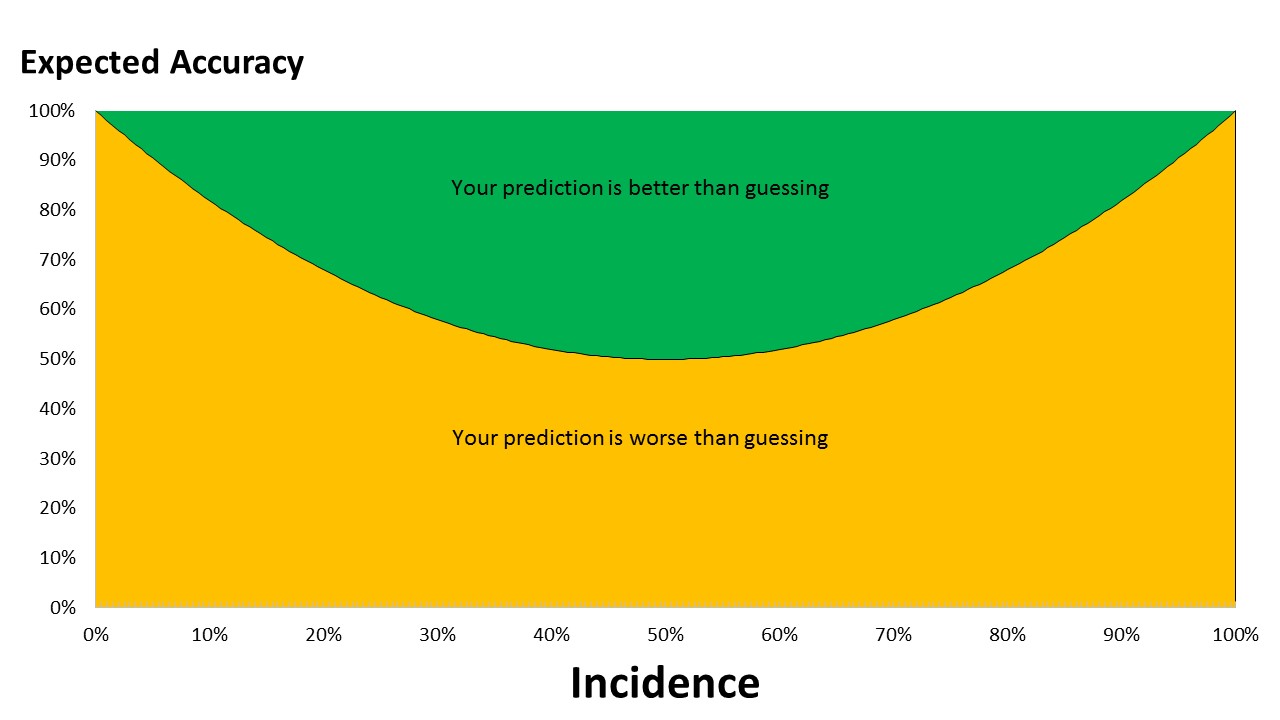
The second rule of thumb is to select those binary variables that have a similar distribution to the variable that you are trying to predict. For example if you are trying to predict a behavior that has 20% incidence among a certain population then the best predictors to use should also have a 20% / 80% spread across two values.
The reason for this condition being optimal is easily explained. The best predictor is one that identifies all cases correctly. Imagine that the best predictor has two possible values with 40% of cases at a value of 1 and 60% of the cases have a value of 2 in this variable. With this distribution, if 1s are predictive of the behavior we are modelling then only half the 1s can be correctly predictive if the behavior has a 20% incidence. The other half of the 1s are incorrectly predictive. However, if the best predictor had 15% of cases that were 1s and 85% cases had a value of 2 then all the 1s could be correctly predictive. This would be a much better predictor to use - in part because the incidence of 1s (or 2s for that matter) is close to the incidence of behavior we are predicting - meaning that 1s have a better chance of being better predictors.
I have a nice graph to show this too. Watch this space!