If your job involves working with lots of different data files and you work in a team that uses these different data sets, finding the latest version can be a time suck. We have an answer for that with two new features we have launched this week.
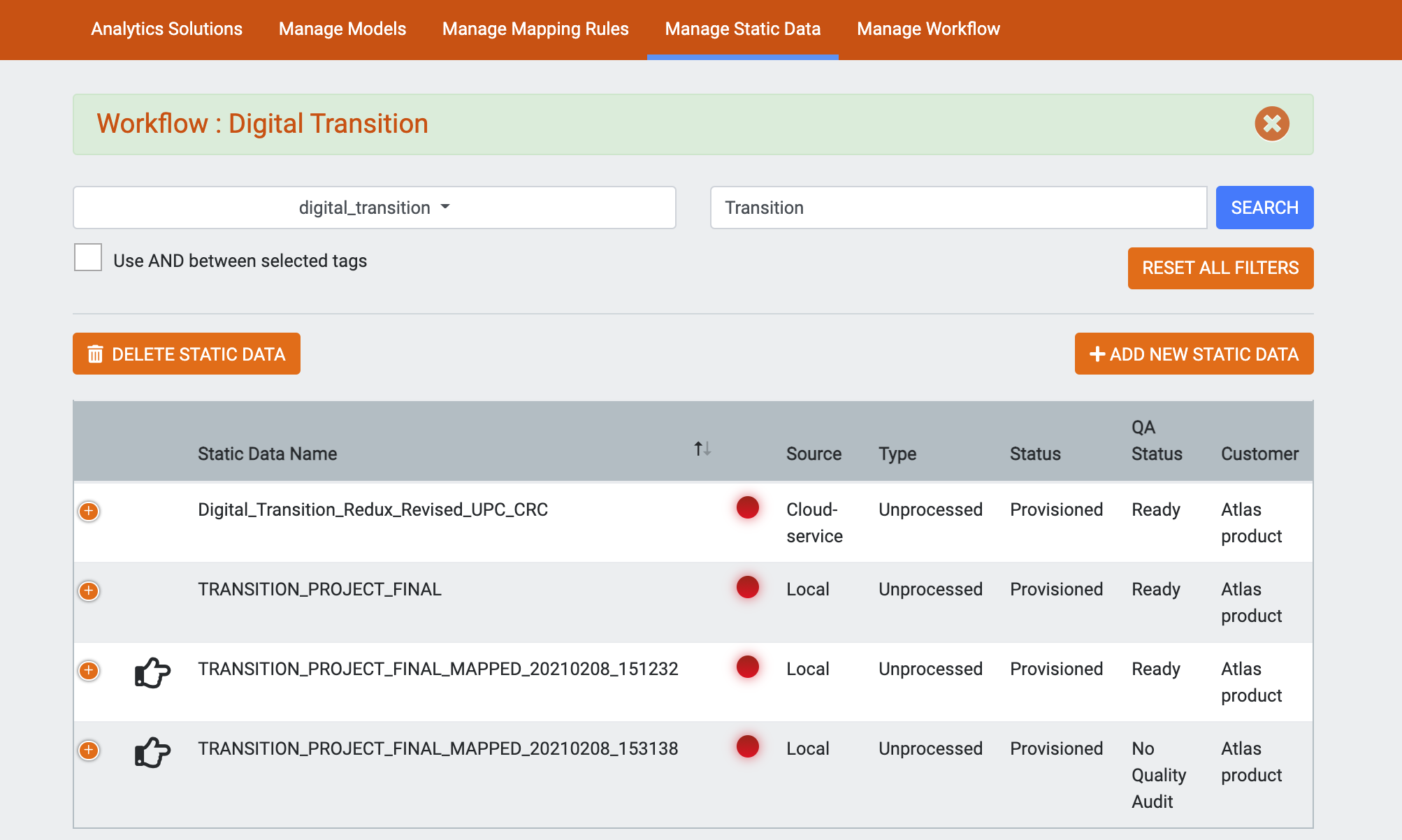
Workflows
The workflows feature lets you view only data sets,reports, charts and operation files that have specific tags assigned. Once a workflow is selected these tags persist through all views in the app.
Bookmarks
This feature bookmarks a specific chart or dataset so that it can be easily found and distinguished from other files and charts in the view. When you have created the perfect chart, bookmark it!