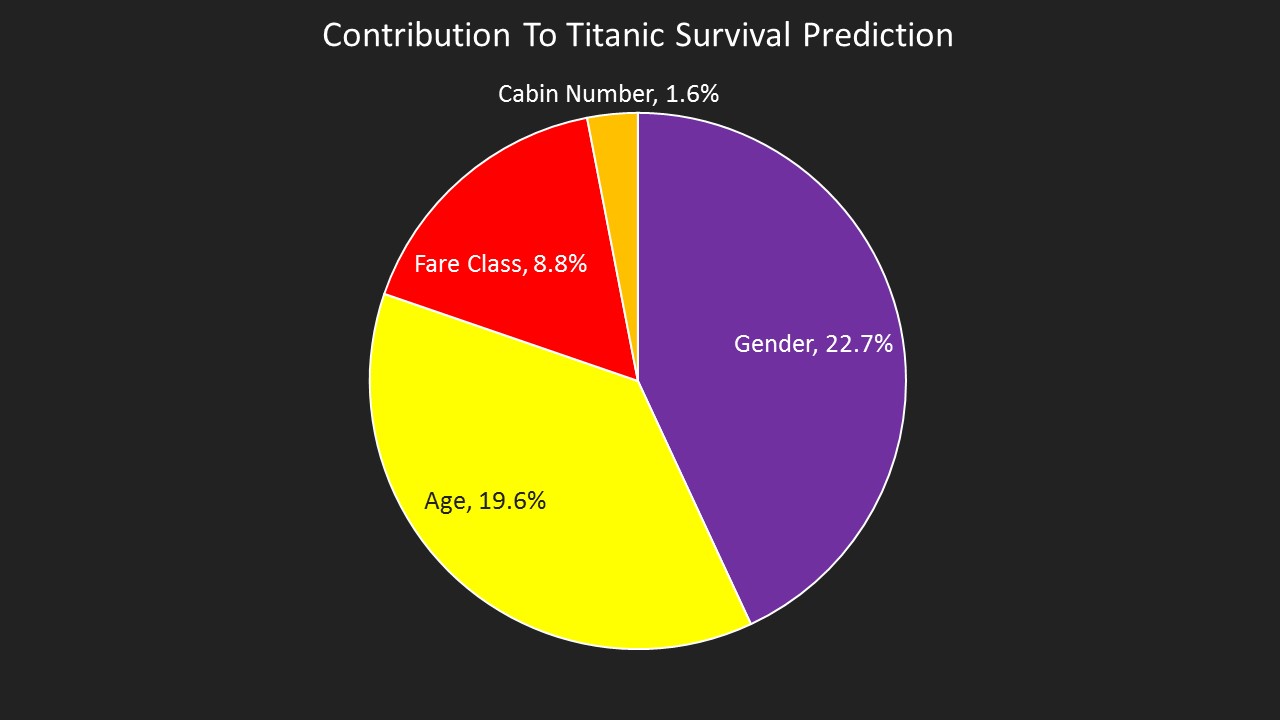
Having worked within an industry (market research) for some time, I am intrigued how other occupations use data, particularly data scientists. After a conversation with a new friend - a data scientist - last week I had a revelation.
Data scientists have created a new words to talk about data analysis. The ones that stand out are features and feature sets. Quantitative market researchers talk about questions and surveys but never features. Essentially, they are the same thing; features are traits, attributes and behaviors of people that can be used to describe/predict specific outcomes. The big difference is that data scientists don't care so much that the features are not human-readable (i.e. they can be read and understood like a book), as long as they help make a prediction. For example, Random Forests make good predictors but aren't easily understandable. The same is true of Support Vector Machines. Excellent predictors but in higher dimensions they are hard to explain.
In contrast, market researchers are fixated on the predictive features being human-readable. As data science has shown, a market researcher's predictions, their stories, will always be weaker than those of a data scientist. This in-part explains the continued trend of story-telling in market research circles. Stories are popular, and contain some ambiguity, this ambiguity can allow people to take out from them what they wish. This is an expedient quality in the short term but damaging long term to the industry.
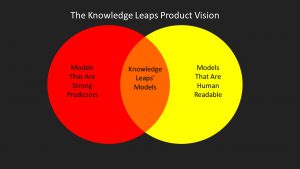
I think market researchers need to change, my aim with Knowledge Leaps is to try and bridge the gap between highly predictive features and human-readable stories.