To test the functionality of the application we have been using some real life data either from people we know who work with data in various companies or from Kaggle (the data science community recently acquired by Google).
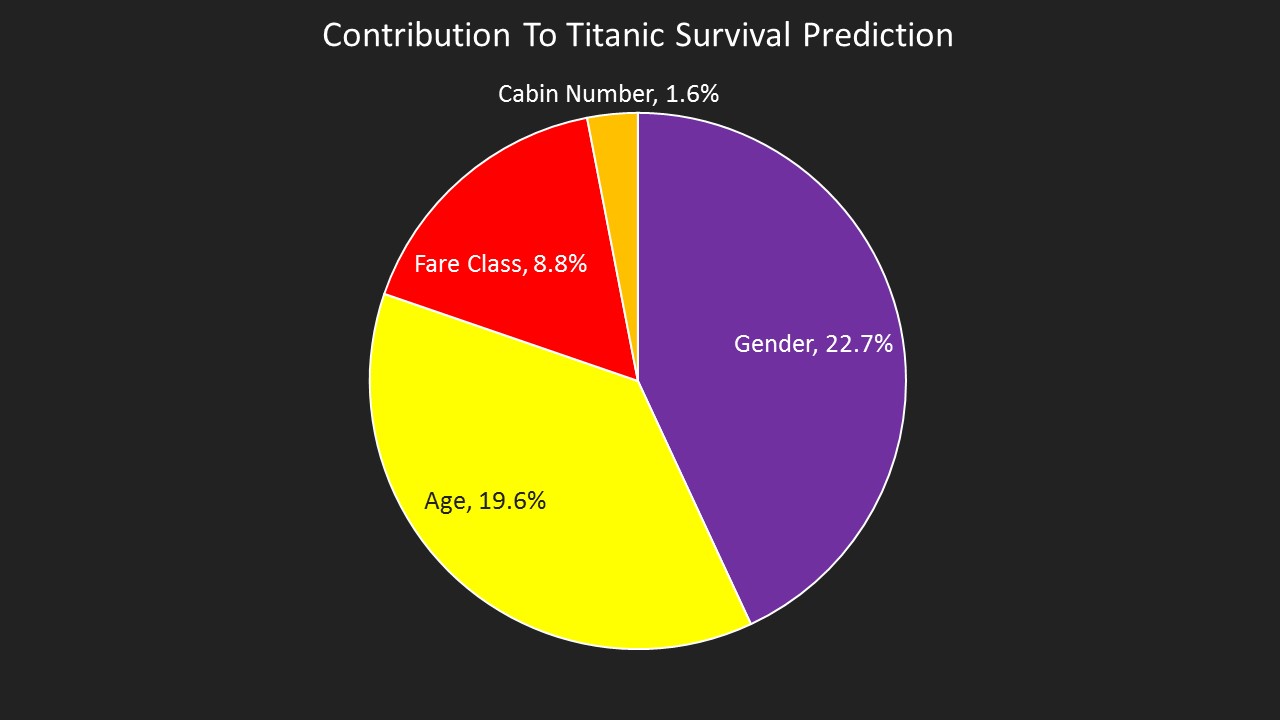
Our favorite test data set from Kaggle is the Titanic survivor data. We like it because there are a small number of records in it (c. 900) and it does not contain many variables (the notable ones are gender, age, point of embarkation, cabin number, cabin level and whether they survived or not).
Kaggle runs competitions to see which data scientist can produce the most accurate prediction of survival. While we are interested in accuracy (the model produced on KL has an accuracy of 80% vs a guessing accuracy of 51% based on the incidence of survivors in the data we have), we are more interested in both accuracy and human readability of the model. This graph shows the outputs of the model drivers, this shows, for example, that a passenger's gender contributes 22.7% of our knowledge about whether they survived or not.
While accuracy is important, being able to relate the model to other people is just as important as it means that we humans can learn, not just machines.