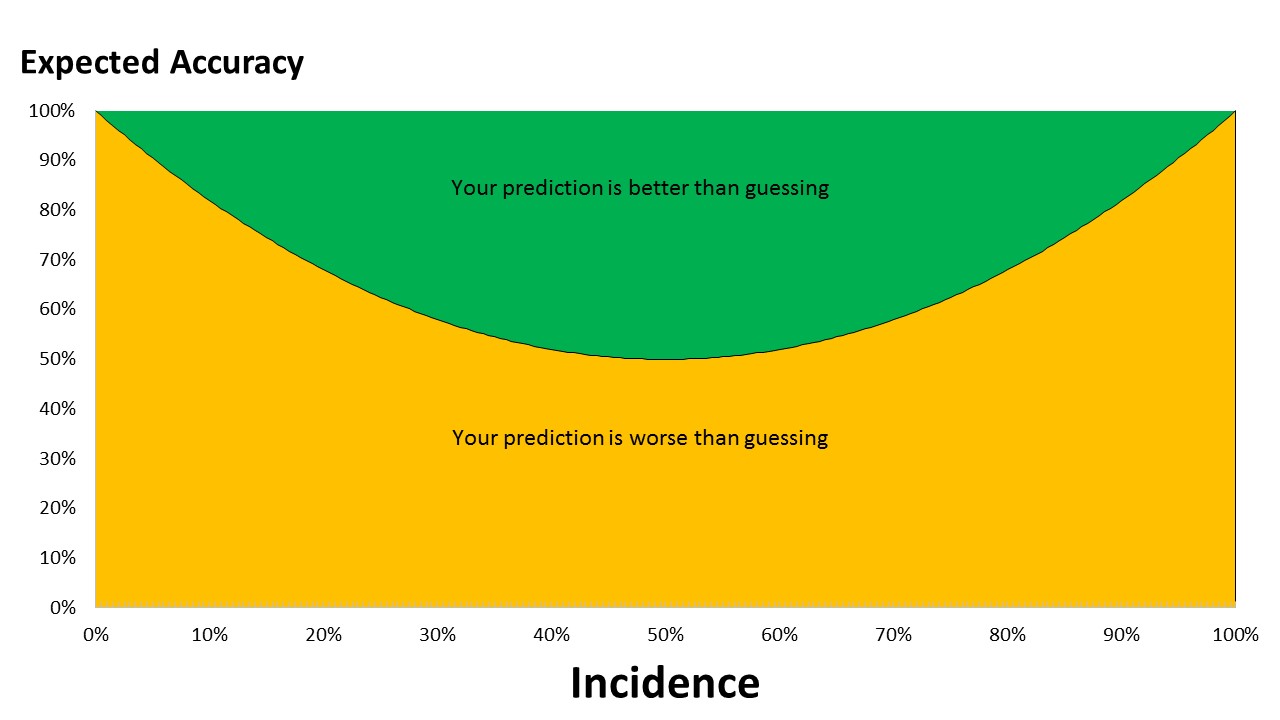
We have been thinking a lot about the relationship between the incidence of the feature we are trying to predict and the usefulness of analytics algorithms. In previous posts (here and here) we looked at the guessing the feature rather than using an analytics model. When the incidence of the feature you are trying to predict is low, it is sometimes worth guessing than running an analytics algorithm since the accuracy will be higher for low incidence features.
If you then consider how Random Forests work (create a family of decision trees at random -> use the modal value predicted by the family as the correctly classified answer), it becomes clear that these are just a mechanism for creating lots of guesses and when the incidence is low, a guess is better than an analytical prediction. Obviously, this isn't to undermine Random Forests, more an observation as to perhaps why they work so well.
We have never really looked at the efficiency of the KL algorithm vs a straight guess as we work down further into a decision tree. However, what we have incorporated is a means of more efficient deployment of resources (servers and processors). The latest release of the product allows users to set a stopping criteria based on the incidence of the predicted feature for a particular branch in the learning tree. As we have seen (here) , incidence levels effect the point at which the user is better off making a guess than relying on an analytics algorithm. The stopping criteria prevents the application going past the point at which a guess would be better.