When it comes to designing and implementing algorithms for Knowledge Leaps I have spent a lot of time thinking about accuracy in relation to making predictions. I soon realized that there is a mathematical relationship between the accuracy of a guess and the incidence of what you are trying to predict.
For instance, if you have built a model for predicting whether or not a roulette ball will fall into the zero slot on a roulette wheel with 37 numbers (0-36) then your model has to be correct (at predicting success or failure) at least 94.67% of the time. However, if you want to predict red or black then your model needs to be correct 50.04% of the time to be better than a pure guess.
The graph below shows the relationship as a function of incidence (the rate of what we are trying to predict).
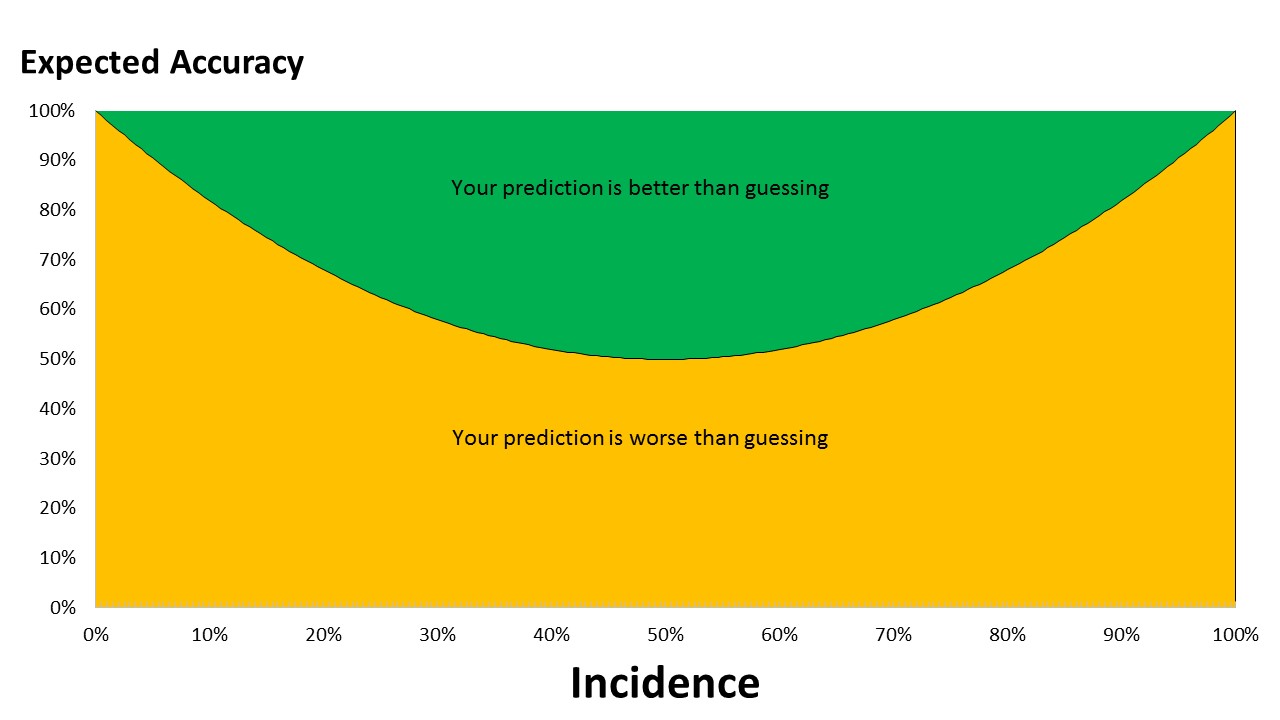
Broad conclusions we can draw from this relationship:
- When we are trying to predict outcomes which have an incidence of between 20% and 80%, there is a lot of potential for producing a worthwhile model that can improve on a guess.
- When the incidence of outcomes is less than 5% and greater than 95%, models need to be delivering 91%+ accuracy to be of any help. This is the realm of medical diagnosis, an area where guesswork isn't welcome.
- Since 66% of the chart is territory where a guess is better than a model, if we produced random models to make a prediction, 66% of the time a guess would be better. Obviously, if we aggregate up the results of lots of random guesses we can produce more accurate predictions (e.g. Random Forests). However we then run into the issue of not creating human readable models.
