There will always be a plentiful supply of data scientists on-hand to perform hand-cut custom data science. For what most businesses requirements, the typical data scientist is over-skilled. Only other data scientists can understand their work and, importantly, only other data scientists can check their work.
What businesses require for most tasks are people with the data-engineering skills of data scientists and not necessarily their statistical skills or their understanding of a scientific-method of analysis.
Data engineering on a big scale is fraught with challenges. While Excel and Google Sheets can handle relatively large (~1mn row) datasets there is not really a similar software solution that allows easy visualization and manipulation of larger data sets. NoSQL / SQL-databases are required for super-scale data engineering, but this requires skills of the super-user. As 'data-is-the-new-oil' mantra makes its way into businesses, people will become exposed to a growing number datasets that are beyond the realm of the software available to them and, potentially, their skill sets.
At Knowledge Leaps we are building a platform solution for this future audience and these future use-cases.The core of the platform are two important features: Visual Data Engineering pipelines and Code-Free Data Science.
The applications of these features are endless; from building a customer data lake, or building a custom-data-pipeline for report generation or even creating simple-to-evaluate predictive models.
Some thoughts on what I have learnt by working in a new company that is building software. A lot of what you "should" do is the wrong thing to do. Here are some reflections on building a firm in San Francisco.
Prospects First
Speaking to prospect firms will get you further, faster than speaking to venture capital firms. Firms that have pain points will pay for solutions and they won't care so much how many other firms have the same pain point. Venture capital firms are interested in size of market, size of outcome, probability of success, experience of the team. Answering a VC's questions won't necessarily help you build a product and a business. If you can't afford to build the software that will answer the pain point you are trying to solve, then work out what you can build and how you can bridge the gap using other means.
Perform The Process By Hand, Before Writing Code
The best business software is first cut-by-hand like the first machine screw. If your software replaces a human-business-process and you can't afford to build the software, ask yourself 'how much can my firm afford to build?'
Most processes have the same elements: Task Specification, Task Execution, Present Results. The most complex part of this is Task Execution as this will require a lot of code and a lot of investment. As your company speaks to firms work out if it is possible to use humans to perform the complex Task Execution element. If you think it is then you should build a software architecture and framework that allows humans to do the hard work at first. This will help you refine the use-case and build more effective and efficient code. This also wouldn't be the first time this has been done, see here and here for more background.
A useful piece of military wisdom is worth keeping in mind; no plan survives first contact with the enemy. While customers are certainly not the enemy, the sentiment still holds. It's not until you put your plan in to action and have firms use your product that you realize its true strengths and weaknesses. Here begins the process of iterating product development.
"Speak to people, we might learn something"
This is what my business development lead says a lot. He also asks questions that get customers and prospects talking. In these moments you will learn about the firm, the buyer, the competition, and lots of other information that will make your product and service better.
"We are just starting out"
This is another useful mantra. In lots of ways we do not know where our journey will take us. It is part inspired by company vision but also customer feedback. In Eric Beinhocker's book, The Origin of Wealth, he likens innovation to the process of searching technology-solution-space, an innovation map, looking for high points (that correlate with company profits and growth). The important part of this search process is customer feedback. What your company does determines you starting point on the innovation map, how your firm reacts to customer and market feedback determines which direction you will go in, and ultimately will be a critical factor in its success.
Data-is-the-new-oil is a useful framework for describing one of the use-cases we are developing our platform for.
Rather than their being just one platform in the create-process-deliver-use data analytics pipeline, a number of different platforms are required. The reason we don't fill our cars up with gasoline at our local oil rig is the same reason why data distribution requires a number of different platforms.
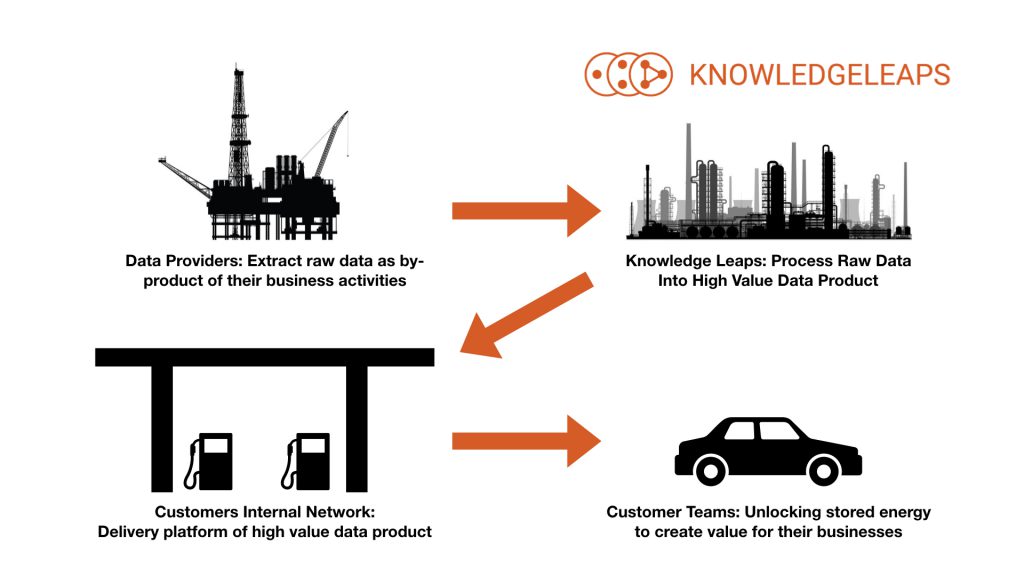
The Knowledge Leaps platform is designed to take raw data from our providers, process and merge these different data feeds before delivering to our customers internal data platforms. Just like an oil-refinery produces the various distillates of crude-oil, the Knowledge Leaps platform can produce many different data products from single or multiple data feeds.
Using a simple UI, we can customize the processing of raw data to maximize the value of the raw data to providers as well as its usefulness to users of the data products we produce.
We just launched the alpha-version of our point-in-time historical brand M&A data base and API. Submit a product code and date the API will return ISIN code (if public) of the owner on that date.
One of the issues with large data files, is that very quickly you come up against the physical laws of the universe; hash function collision rates have meaningful impact on how exhaustive your calculations are and unbounded memory structures create significant performance issues.
With our KL app, we are building technology to get round that. As our Maximum Viable File Size has grown from thousands of rows, to millions of rows and now to billions of rows we realized that the laws of physics are a real nuisance when analyzing data.
To that end, we have rolled out a data sampling feature that allows users to run analysis on a randomized subset of a data file. When speed of analysis is important then this feature allows users to get round the laws of physics and produce representative results.

The objective behind the redesign is to make better use of screen real estate, to ease navigation and simplify work flows. Since we began development, the product has become more complex, by necessity. Making it simple and easy to use is central to the brief.
The rolling brief of "simplify" will continue to be used as the capabilities of the platform become more advanced. The UI will continue to evolve as more features are launched. In this release we have added the following features:
Data formats - users can now import zipped files, comma- , semicolon-, and pipe-delimited data files structures. For parsing we now have automatic detection of delimiters.
Column Reduction - users can use this feature to delete fields in the data and save a new, reduced, version of the data. This is a useful feature for stripping out PII fields or fields that contain "bloat". Improving performance and enhancing security.
Data Extraction - users can extract unique lists of values from fields in a data set. The primary use case for this feature is to allow users to create audiences based on behaviors. These audiences can then be appended to new data sets to identify cross-over behavior.
Data Sampling - users can randomly sample rows from a data file. For very large data sets, performing exhaustive calculations is time and resource intensive. Sampling a data set and analyzing a subset is based on sound statistical principles and rapidly increases productivity for large data sets.
Transform Filters - users can transform a filter in to a mapping file. Data reduction is an important step in data analysis, converting filters into data reduction maps will make this effortless.
Dynamic Mapping - users can access API end points, pass values to the end point and take the returned value as the "mapped value". Initially this will be limited to an internal api that maps product code to brand and owner. New API connections will be added over time.
Multiple AWS Accounts - users can now specify multiple AWS account access keys to connect to. This is to incorporate the launch of KL data products. KL now offers a range data products that firms can subscribe to. Multiple AWS account capabilities allows for customers to bring many different data streams into the account environment on the platform.
As well as building solutions that can be accessed through a simple form/button led UI, these features are the building-blocks of future analytics solutions. These features are be platform-wide universal tools, untethered from a specific context or environment. This will give our product development team greater flexibility to design and implement new functions and features.
The patent that has just been awarded to Knowledge Leaps is for our continuous learning technology. Whether it is survey data, purchase data or website traffic / usage data., the technology we have developed will automatically search these complex data spaces. The data spaces covers the price-demand space for packaged goods, or the attitudinal space of market research surveys and other data where there could be complex interactions. In each case, as more data is gathered - more people shopping, more people completing a survey, more people using an app or website - the application updates its predictions and builds a better understanding of the space.
In the use-case for the price-demand for packaged goods, the updated predictions then alter the recommendations about price changes that are made. This feedback loop allows the application to update its beliefs about how shoppers are reacting to prices and make improved recommendations based on this knowledge.
In the survey data use-case, the technology will create an alert when the data set becomes self-predicting. At this point capturing further data is unnecessary to understand the data set and carries an additional expense.
The majority of statistical tools enable analysts to identify the relationships in data. In the hands of a human, this is a brute-force approach and is prone to human biases and time-constraints. The Knowledge Leaps technology allows for more systematic and parallelized approach - avoiding human bias and reducing human effort.

The invention of currency by society is as important as the spread of organized religion. Unlike religion, we have yet to fully grasp the power of price.
Yet for something so important, most companies do not understand the power of price. Firms know how to price items, but pricing strategies are largely built on one of three, arguably flawed, methodologies:
Each method is flawed to some degree, and invariably means firms either leaving money on the table, or do not maximize sales in a competitive context.
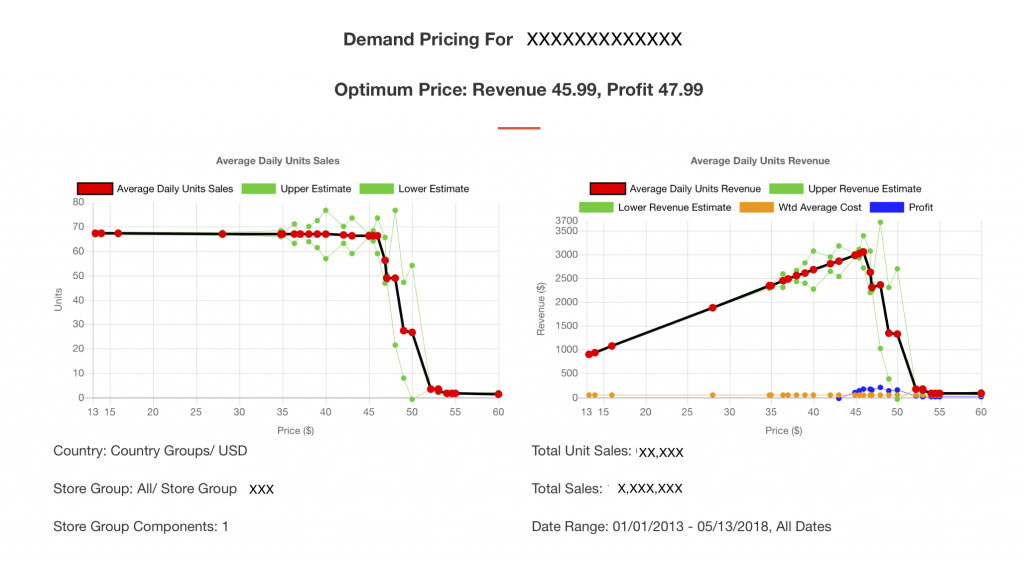
Knowledge Leaps has created an algorithm to estimate the optimum pricing based on consumer demand. The platform can evaluate price in different contexts (peak vs. off-peak seasons, stand-alone pricing Vs competitive context pricing, test vs. control stores, and by different audiences).
Using our algorithm we can quickly evaluate multiple items across multiple store groups in multiple territories/countries to identify optimum price zones.
Overlaying machine learning the KL platform will identify how a retailer can increase profit at a transaction level and then test it in the market place to explore any unintended consequences of price changes.